Tuning Engines
Tuning Engines is a unified platform to securely govern, optimize, and deploy any AI model through one API with transparent pricing.
Visit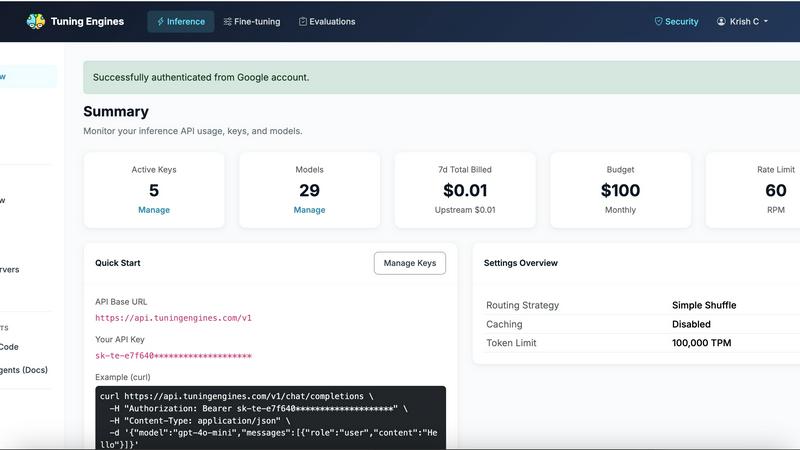
About Tuning Engines
Tuning Engines is a unified AI control and governance layer built for teams that need to move beyond isolated experiments into a secure, observable, and cost-aware production environment. At its core, Tuning Engines provides a single platform where organizations can manage the entire AI lifecycle: from inference and model routing to fine-tuning, evaluations, and policy enforcement. The product is designed for developers who want OpenAI-compatible and Anthropic-compatible APIs, CLI workflows, and integrations with tools like Claude Code, Cursor, and VS Code. It is equally built for administrators who need role-based access, per-key budgets, rate limits, guardrails, and full auditability. The fundamental value proposition is simple: you access any model through one API endpoint, with centralized policy control and token economics managed by design. Tuning Engines passes through infrastructure costs at-cost with zero markup, so you only pay for support and platform upkeep. This approach removes the complexity of managing multiple model providers, GPU infrastructure, and governance tools separately. Instead, you get one runtime where models can be trained, evaluated, routed, governed, and used by agents and tools at scale. Whether you are building code assistants, conversational AI, agentic systems, or enterprise RAG pipelines, Tuning Engines gives you the foundational layer to operate with confidence.
Features of Tuning Engines
Unified Inference
One OpenAI-compatible endpoint gives you access to over 100 models including open weight models like Llama 3.3 70B, DeepSeek V3, and Qwen 2.5, as well as commercial frontier models and your own tuned variants. You keep your existing SDK and simply swap one base URL. Every request goes through centralized policy, full auditability, and token controls. Streaming and structured output are supported out of the box.
Model Tuning
You can adapt open models to your specific data, workflows, and production goals using supervised fine-tuning and LoRA adapters. Tuning Engines handles the GPU infrastructure so you do not need to manage hardware or cold starts. After tuning, your custom models are available through the same unified endpoint alongside all other models, making deployment seamless.
Policy and Governance
Administrators get complete control over every AI interaction through role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, and policy-as-code with AGT YAML policies. Every request is traced with runtime traces, data capture, and usage analytics. This gives you the auditability and tenant isolation required for production environments.
Evaluation Gates
You can measure model quality, compare variants, and ship with evidence. Evaluation tools let you run systematic tests against your tuned models and compare them to baseline models. This ensures that quality moves with your business needs and that you have data to support deployment decisions.
Use Cases of Tuning Engines
Code Assistance
Teams building IDE copilots, code generation tools, refactoring agents, and debugging assistants can use Tuning Engines as their unified backend. Connect tools like Cline, Continue.dev, Cursor, VS Code, and Windsurf through a single governed platform. Developers get the same API they already know, while administrators enforce policies and track usage across the entire team.
Conversational AI
Customer support bots, internal helpdesks, and multilingual chat applications benefit from the ability to route between models based on cost, quality, or latency requirements. You can set fallback policies so if one model fails or hits a rate limit, another model handles the request automatically. Guardrails ensure responses stay within policy boundaries.
Agentic Systems
Multi-step reasoning, planning, and tool-using execution pipelines require reliable model access and governance. Tuning Engines provides MCP servers, reusable skills, and agent integrations that let you build complex agent workflows. The platform captures runtime traces so you can debug and audit every step your agents take.
Enterprise RAG
Secure, scalable retrieval over knowledge bases and private documents requires tight control over data and model access. Tuning Engines gives you tenant isolation, credential sources, and policy enforcement so that sensitive information stays protected. You can fine-tune models on your domain data and serve them through the same governed endpoint.
Frequently Asked Questions
How does Tuning Engines handle model routing and fallbacks?
Tuning Engines allows you to define routing profiles that determine which model handles each request based on criteria like cost, latency, or quality. You can also set fallback rules so that if the primary model fails, returns an error, or hits a rate limit, the system automatically routes to a secondary model. This ensures high availability and predictable performance without manual intervention.
What models are available through the unified API?
The platform provides instant access to over 100 models including open weight models like Llama 3.3 70B, Llama 3.1 8B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, and Whisper Large v3. You also get access to commercial frontier models and any model you fine-tune with Tuning Engines. All models are available through the same OpenAI-compatible endpoint.
How does pricing work for Tuning Engines?
Tuning Engines passes through infrastructure costs at-cost with zero markup. This means you pay exactly what the underlying GPU and compute resources cost. You only pay Tuning Engines for platform support and upkeep. This transparent pricing model removes the typical markup that other providers add to model inference and fine-tuning.
Can I integrate Tuning Engines with my existing development tools?
Yes, Tuning Engines is designed to work with your existing workflows. It provides OpenAI-compatible APIs so you can use your current SDK with a simple base URL swap. It also supports CLI workflows, MCP access, and integrations with coding agents like Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, and Windsurf. This means you do not need to rewrite your stack or learn new tools.
Similar to Tuning Engines
Distro is an AI Distribution Operator that helps B2B teams publish content, find buyer conversations, engage prospects, and turn social intent into pi
Polymarket Trading Bot For Crypto
Skygen AI is a platform that lets you give it a task and it handles the work, from building websites to analyzing data.
HyperLake provides a sovereign AI infrastructure that enables autonomous agents to operate efficiently with zero compute markup in your cloud.
Minded enables you to effortlessly train AI agents to handle tasks and enhance customer service using simple, natural language.
YCaaS provides comprehensive AI agents that efficiently manage all tasks and roles from start to finish, streamlining your operations.
xyOps is a workflow automation system that lets you schedule, monitor, and respond to events across your entire infrastructure from one place.
Playwriter lets AI agents control your actual Chrome browser with all your logins and extensions intact.