Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Agenta centralizes prompt management and evaluation, enabling reliable LLM development through structured collaboration.
Last updated: March 1, 2026
OpenMark AI benchmarks over 100 language models on your specific task to find the best one for cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
Agenta
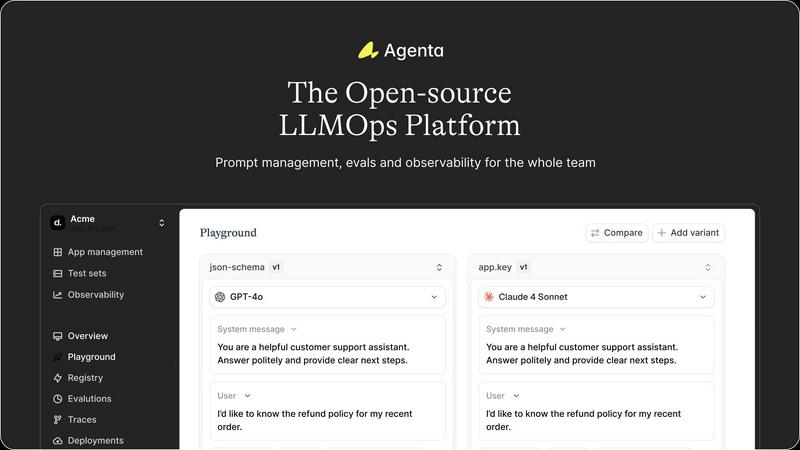
OpenMark AI

Feature Comparison
Agenta
Centralized Prompt Management
Agenta allows teams to centralize their prompts, evaluations, and traces in one comprehensive platform. This eliminates the disorganization often found in scattered tools like Slack and Google Sheets, enabling seamless collaboration among team members.
Automated Evaluation System
The platform features an automated evaluation system that replaces guesswork with evidence-based insights. Teams can systematically run experiments, track results, and validate every change, creating a reliable foundation for decision-making.
Unified Playground for Experimentation
Agenta includes a unified playground that enables teams to compare prompts and models side-by-side. This feature supports iterative development by allowing teams to test and refine their prompts in a controlled environment.
Comprehensive Observability Tools
With built-in observability tools, Agenta offers the ability to trace every request and identify exact failure points. The platform facilitates annotation of traces, enabling teams to gather user feedback and turn any trace into a test with a single click.
OpenMark AI
Plain Language Task Description
You do not need to write complex code or structured prompts to begin benchmarking. OpenMark AI operates on a simple, foundational principle: describe what you want the AI to do in your own words. The platform interprets your intent, whether it's "classify customer emails by sentiment" or "extract dates and names from legal documents," and constructs the necessary tests. This removes the technical barrier, allowing product managers and developers to focus on the task's objective rather than the intricacies of prompt engineering for multiple APIs.
Multi-Model Comparison in One Session
The platform enables you to test the same prompt or task against dozens of different LLMs simultaneously. This is a core differentiator from manual testing, where you would have to run separate, sequential calls to each model's API. With OpenMark AI, you launch one benchmark job and receive a unified results dashboard. This side-by-side comparison is essential for a clear, apples-to-apples evaluation of performance, putting models from different providers on an equal footing based on your specific criteria.
Holistic Performance Metrics
OpenMark AI moves beyond simple accuracy or speed. It provides a complete picture of model suitability by measuring four key dimensions: the quality of the output (scored against your task), the real cost per API request, the latency (response time), and the stability of the model across multiple repeat runs. Seeing the variance in outputs is critical; it tells you if a model is dependable or if its first successful response was a fluke. This holistic view is what allows for true cost-efficiency analysis—finding the best quality relative to what you pay.
Hosted Benchmarking with Credits
To simplify access and comparison, OpenMark AI uses a credit-based system. You do not need to source, configure, and manage separate API keys and accounts for every model provider you wish to test. This eliminates significant setup overhead and billing complexity. You purchase credits through OpenMark AI, and the platform handles all the backend API calls to its supported catalog of models. This foundational approach makes large-scale benchmarking accessible and manageable for teams of any size.
Use Cases
Agenta
Collaborative Prompt Development
Agenta is ideal for collaborative prompt development, where product managers, developers, and domain experts can work together to iterate and refine prompts. This collaboration leads to more robust and effective LLM applications.
Performance Monitoring and Debugging
AI teams can utilize Agenta to monitor production systems and detect regressions in real time. With its observability features, teams can quickly identify and address performance issues, enhancing the reliability of their applications.
Structured Experimentation
Agenta provides a structured environment for experimentation. Teams can run side-by-side comparisons of different models and prompts, allowing them to make data-driven decisions based on systematic evaluations.
Integration with Existing Workflows
Agenta seamlessly integrates with popular frameworks like LangChain and OpenAI, making it easy to incorporate into existing workflows. This ensures that teams can leverage their current tools while benefiting from Agenta's structured approach to LLM development.
OpenMark AI
Validating a Model Before Feature Shipment
A development team has built a new AI-powered feature, such as an automated support ticket categorizer. Before launching it to real users, they use OpenMark AI to validate their chosen model. They describe the categorization task, run it against several potential models, and compare not just accuracy but also cost and response consistency. This ensures they deploy the most reliable and cost-effective model from day one, preventing poor user experiences and unexpected API bills.
Choosing Between Models for a Specific Workflow
A product manager needs to select an LLM for a new data extraction pipeline that processes research papers. They have a shortlist from various vendors. Using OpenMark AI, they create a benchmark using sample paragraphs from their domain. The results clearly show which model provides the most accurate and consistent entity extraction at a sustainable cost per document, providing a data-driven foundation for the procurement and technical implementation decision.
Testing Model Consistency and Stability
A developer notices that their current AI integration occasionally produces bizarre or off-topic responses, though it often works well. They use OpenMark AI's repeat-run capability to execute the same prompt multiple times for several candidate replacement models. The variance analysis in the results immediately highlights which models produce stable, predictable outputs every time and which ones suffer from the same inconsistency, guiding them toward a more robust solution.
Cost-Efficiency Analysis for Scaling Applications
An engineering lead is planning to scale an existing AI chat feature from hundreds to hundreds of thousands of users. They use OpenMark AI to benchmark their current model against newer, potentially cheaper alternatives. By comparing the real API cost per request alongside the quality scores for their specific conversation patterns, they can calculate the total cost of ownership at scale and make a strategic decision that balances budget with performance.
Overview
About Agenta
Agenta is an open-source LLMOps platform tailored for AI teams that aim to develop and deploy reliable large language model (LLM) applications. Designed to bridge the communication gap between developers and subject matter experts, Agenta creates a collaborative workspace that facilitates experimentation with prompts, performance evaluation, and effective debugging of production issues. The platform addresses significant challenges faced by AI teams, including the inherent unpredictability of LLMs and the disjointed workflows that often occur across various tools. By centralizing the entire LLM development process, Agenta enhances team productivity and significantly reduces the time typically spent on debugging. With a structured approach to LLM development, Agenta empowers teams to adhere to best practices, streamline their workflows, and ultimately deliver high-quality LLM applications more efficiently. Whether you are a developer, product manager, or domain expert, Agenta provides the tools necessary for effective collaboration and innovation in AI development.
About OpenMark AI
OpenMark AI is a fundamental tool designed to solve a critical problem in modern software development: choosing the right large language model (LLM) for a specific task. It is a web application for task-level LLM benchmarking. Instead of relying on marketing claims or generic leaderboards, OpenMark AI allows developers and product teams to test models based on their actual, unique needs. You simply describe the task you want to perform in plain language, such as data extraction, translation, or question answering. The platform then runs your prompts against a wide catalog of models in a single session, using real API calls. The core value lies in the comprehensive comparison it provides. You see not just a single output, but side-by-side results for cost per request, latency, scored quality, and, crucially, stability across repeat runs. This shows variance, revealing which models are consistently reliable versus those that just got lucky once. By using a hosted credit system, it eliminates the complex setup of managing multiple API keys from providers like OpenAI, Anthropic, or Google. OpenMark AI is built for making informed, pre-deployment decisions, ensuring you select a model that offers the best balance of quality, cost-efficiency, and consistency for your specific workflow before you ship an AI feature to users.
Frequently Asked Questions
Agenta FAQ
What is LLMOps and how does Agenta fit into it?
LLMOps refers to the practices and tools used to manage the lifecycle of large language models. Agenta fits into this by providing a structured platform that centralizes prompt management, evaluation, and observability, streamlining the LLM development process.
How does Agenta facilitate collaboration among team members?
Agenta fosters collaboration by allowing product managers, developers, and domain experts to work together in one unified platform. It provides tools for prompt iteration, evaluation, and debugging, enabling real-time collaboration and feedback.
Can Agenta be integrated with other AI frameworks?
Yes, Agenta is designed to integrate seamlessly with various AI frameworks, including LangChain and OpenAI. This flexibility allows teams to utilize Agenta alongside their existing tools without disruption.
What kind of support does Agenta provide for debugging?
Agenta offers comprehensive observability tools that trace requests and identify failure points. This allows teams to annotate traces, gather feedback, and quickly debug issues, reducing the time and effort spent on troubleshooting.
OpenMark AI FAQ
How does OpenMark AI score the quality of model outputs?
OpenMark AI scores quality based on the specific task you define. For structured tasks like classification or extraction, it can use automated checks against expected formats or answers. For more creative or open-ended tasks, the platform may guide you to review and score outputs manually, or use comparative grading. The fundamental goal is to measure how well each model's output fulfills the intent you described, providing a task-relevant quality metric beyond generic benchmarks.
Do I need my own API keys to use OpenMark AI?
No, you do not need to provide or configure any external API keys. OpenMark AI operates on a hosted credit system. You purchase credits through the platform, and it manages all the API calls to its supported catalog of models from providers like OpenAI, Anthropic, Google, and others. This is a core feature designed to remove setup complexity and allow for seamless, centralized comparison across different vendors.
What is the benefit of testing stability with repeat runs?
Testing stability by running the same prompt multiple times is crucial because LLMs can be non-deterministic, meaning they don't always give the same answer to the same question. A single successful output might be lucky. By observing variance across repeat runs, you see which models are consistently reliable for your task. This helps you avoid deploying a model that will confuse users with erratic behavior, ensuring a more dependable and professional end-user experience.
What kinds of tasks can I benchmark with OpenMark AI?
You can benchmark virtually any task you would use an LLM for. Common examples include text classification, translation, summarization, question answering, data extraction from documents, code generation, and testing responses for a Retrieval-Augmented Generation (RAG) system. The platform is built to be flexible. If you can describe the task in plain language, you can likely create a benchmark for it to find the optimal model.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform that centralizes the management, evaluation, and debugging of large language models (LLMs) for AI teams. It addresses the unique challenges faced by developers and subject matter experts in creating reliable AI applications. Users often seek alternatives due to various reasons, including pricing, specific feature sets, or compatibility with their existing workflows and platforms. When choosing an alternative, it is essential to consider factors such as ease of use, integration capabilities, support options, and the overall effectiveness in enhancing LLM development processes.
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level benchmarking of large language models. It allows teams to test many LLMs simultaneously on their specific use case, comparing real-world metrics like cost, latency, output quality, and stability. This helps in making informed, pre-deployment decisions about which model to integrate into a product. Users may explore alternatives for various reasons. Some might seek different pricing structures or free tiers with more generous limits. Others may require features like on-premises deployment, integration with specific development environments, or support for a different set of models not covered by the current catalog. When evaluating other options, consider the core need: objective, apples-to-apples comparison. Look for tools that test with real API calls, provide metrics beyond just speed and cost, and offer insights into output consistency. The goal is to find a solution that delivers actionable data to confidently select the right model for your workflow and budget.