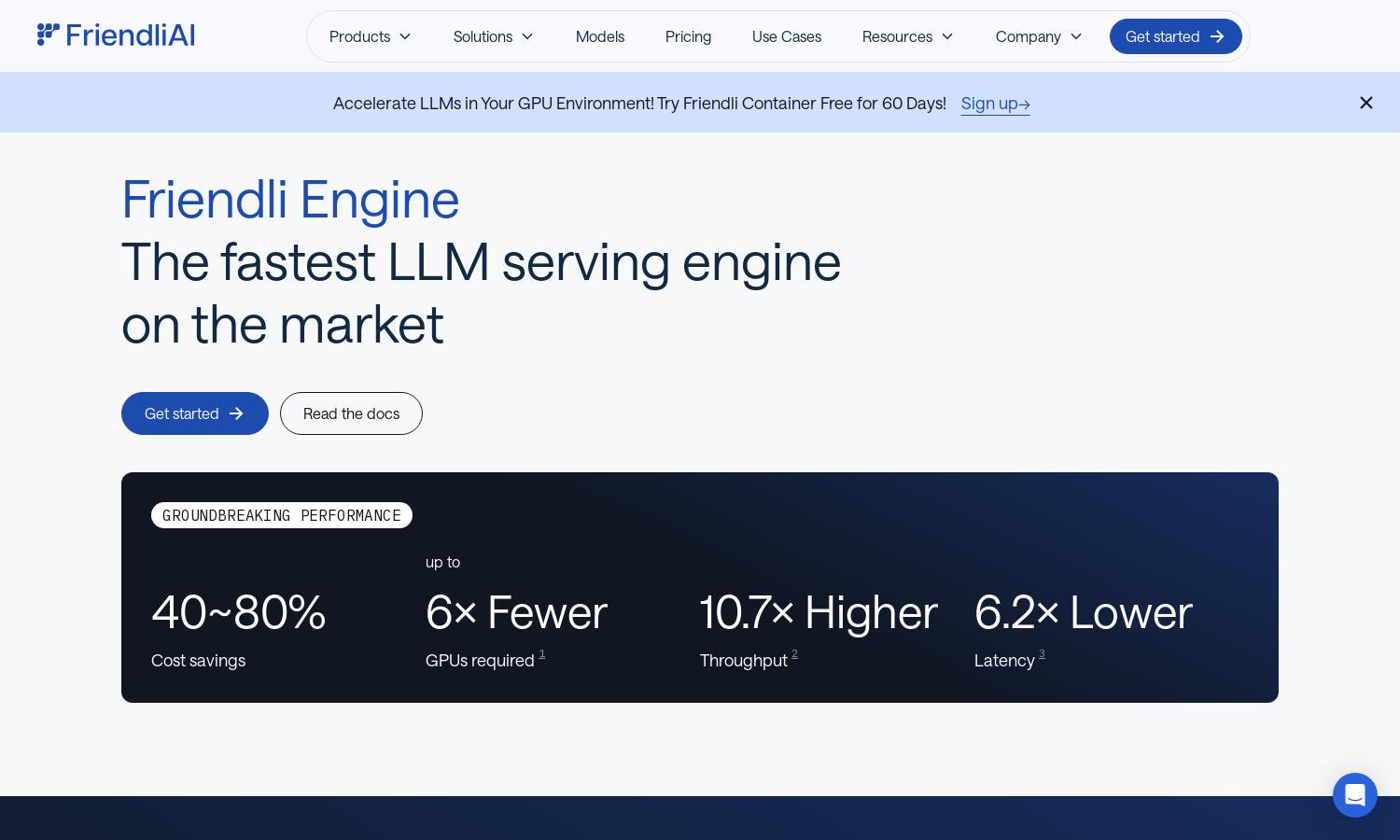
Friendli Engine
About Friendli Engine
Friendli Engine is a premier platform for generative AI, specializing in fast and cost-effective LLM inference. Targeted at businesses and developers, it utilizes innovative technologies like iteration batching for higher throughput and lower latency. Its unique capabilities enable efficient deployment while slashing operational costs, making it an indispensable tool.
Friendli Engine offers flexible pricing plans tailored to various user needs, including free trials for newcomers. Subscription tiers vary, providing enhanced benefits such as advanced features and improved performance. Upgrading unlocks powerful tools that maximize efficiency, making it suitable for those aiming for cost-effective and rapid deployment.
Friendli Engine features an intuitive user interface designed for seamless navigation. Its layout ensures a smooth browsing experience, highlighting unique attributes like easy model configuration and rapid API access. This user-friendly design simplifies the deployment of generative AI models, catering to both developers and businesses alike.
How Friendli Engine works
Users begin by signing up on Friendli Engine, where they can choose from three primary service options for deploying LLMs. After onboarding, users interact with the platform to configure and deploy generative AI models with ease. They utilize features like iterative batching and multi-LoRA serving, enabling efficient performance optimization for their specific use cases.
Key Features for Friendli Engine
High Performance LLM Inference
Friendli Engine delivers groundbreaking performance for LLM inference, achieving up to 10.7x higher throughput and significantly reduced latency. This unique feature optimizes generative AI applications by efficiently processing requests, providing users with exceptional speed and cost savings in comparison to traditional engines.
Multi-LoRA Support
Friendli Engine's multi-LoRA support allows simultaneous usage of various LoRA models on fewer GPUs. This efficiency makes LLM customization accessible, reducing resource requirements while maintaining peak performance. Users can scale their models effectively, ensuring versatile deployment for diverse applications and use cases.
Speculative Decoding
The speculative decoding feature in Friendli Engine enhances LLM inference by predicting future tokens during the generation process. This unique capability accelerates response times without compromising output accuracy, enabling faster interactions and improving overall user experience in generative AI applications.
You may also like: